连接数据
有数BI目前支持的数据源有:
| 数据源 | |||
|---|---|---|---|
| Excel | CSV | MySQL | TiDB |
| MaxCompute | AnalyticDB for MySQL | Amazon Redshift | Oracle |
| SQL Server | Db2 | 达梦 | MapR Hadoop Hive |
| Spark SQL | Apache Kylin | Kyligence | Apache Impala |
| Apache Druid | Doris | ClickHouse | Elasticsearch |
| MonetDB | Cheetah | HANA | GreenPlum |
| Transwarp Inceptor | teradata | prestodb | PostgreSQL |
| InfluxDB | NTSDB | Vertica | 有数大数据平台(仅域内) |
| 数据填报 | Restful API | 自定义API | Phoenix |
新建数据连接
在分析开始之前,我们需要做的
第一步就是连接数据,如下图所示(以连接MySQL数据库为例):

下面我们分步骤介绍:
1、在“数据源”模块,添加数据连接

2、选择要添加的数据连接类型

3、填写数据库信息后保存即可完成数据连接的添加

缓存有效期的解释
可以看到,在数据库设置的页面,有一项“缓存有效期”的设置。为了提升访问性能,访问报告时,有数会对查询到的结果数据进行缓存,以便下次访问相同数据时加载速度更快。“缓存有效期”则指定了缓存在有数系统内存留的时间。比如缓存有效期设置为1小时,则首次访问报告会进行缓存,1小时内再次访问相同报告时会直接读取缓存数据,1小时之后再访问报告,缓存已经失效,会重新访问数据库获取最新的数据并重新进行缓存。 因此,为了提高访问性能,同时又要保证数据的时效性,建议缓存有效期的设置跟所连接的数据库的更新周期保持一致。(比如所连接的MySQL数据库会在每日的凌晨6点更新数据,则可以将该数据连接的“缓存有效期”设置为“1天”,“缓存失效点”设置为“06时00分”)

数据连接信息的查看
已建立的数据连接会显示在数据连接列表中,除了基本信息,我们还可以在有数系统中查看选中的数据连接的“表信息”、“相关内容”、“操作记录”。
1、表信息:会显示选中数据连接的所有数据表。数据表分为“原始表”跟“自定义表”两种类型,“原始表”指的是数据库中已存在的表,“自定义表”指的是在网易有数内通过输入SQL建立的自定义视图(注:自定义视图只存储SQL逻辑,查询的数据不会落库存储)。另外可以设置抽取,将数据库中的表抽取至有数提供的速度更快的MPP内存数据库,关于抽取的设置跟管理,会在后续章节进行更详细的介绍,初学者暂时不需要了解此功能。

点击数据表的名称,可以在弹出的窗口中预览数据表的数据。

维度分类中支持对表添加描述
2、相关内容:在“相关内容”可以查看基于该数据连接建立的数据模型跟报告,点击名称可以快速跳转至对应的数据模型或报告。

3、操作记录:会显示用户对该数据连接的操作记录。我们会记录的行为包含以下几种:添加/修改数据连接、添加/修改/删除/暂停抽取任务、添加/修改/删除自定义表。

4、字段配置:支持对数据连接下表粒度的字段配置,一次配置同步至所有相关模型,提高配置效率。
具体演示如下:

▚ 在使用 Elasticsearch 数据源时,有些需要注意的问题
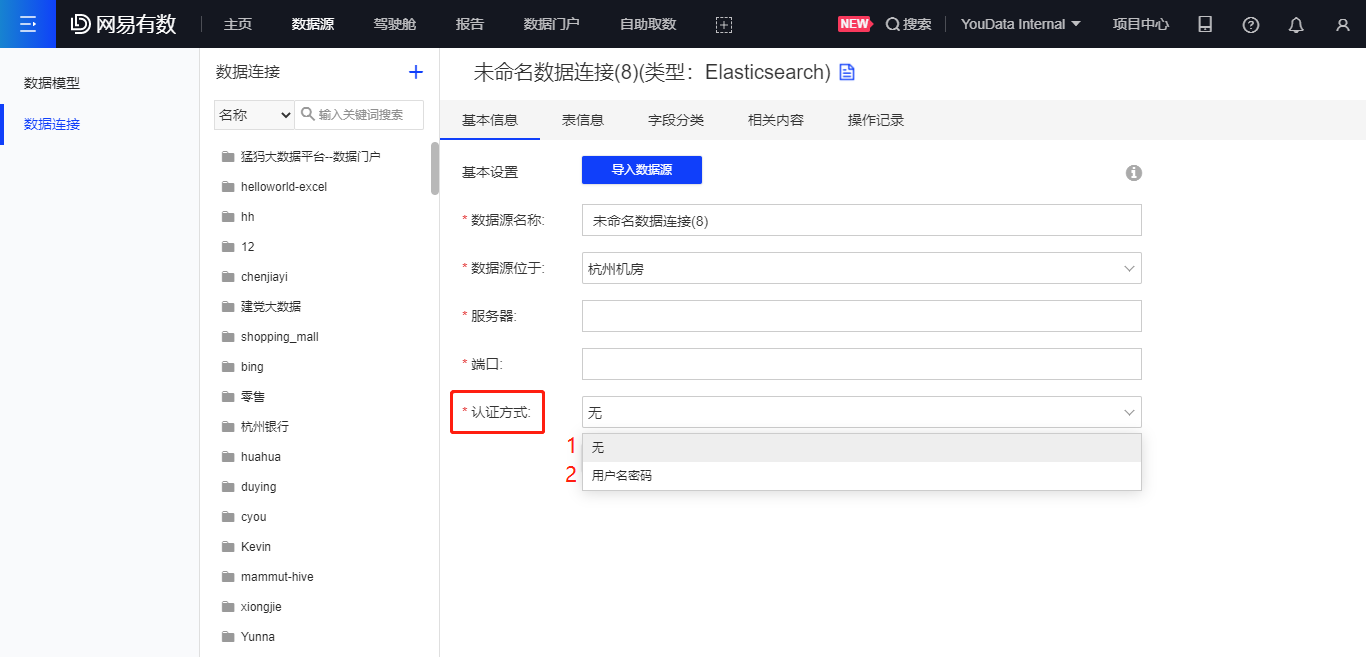
① 要求 Elasticsearch 版本为6.3以上,并且开启了 xpack 的 SQL 支持 ② 针对 Elasticsearch 数据源的认证方式有数支持两种:无/用户名密码
③ 只有 mapping 中每个 field 与 type 一一对应,与 RDB 中建模相同形式的 index 才能够在有数中使用
例如:
{
"mock_table_1": {
"mappings": {
"properties": {
"A": {
"type": "keyword"
},
"SA": {
"type": "long"
},
"T": {
"type": "date"
}
}
}
}
}④ 若mapping 中包含嵌套的结构,有数无法明确获取其 schema, 这样的 index 便不能在有数中使用
例如:
{
".kibana_1": {
"mappings": {
"doc": {
"dynamic": "strict",
"properties": {
"config": {
"dynamic": "true",
"properties": {
"buildNum": {
"type": "keyword"
}
}
},
"updated_at": {
"type": "date"
}
}
}
}
}
}